Eight Days in China: What I Learned from the AI Labs, Robotics Startups and Academia






Published: May 13, 2026
Source: https://matthewdwhite.substack.com/p/eight-days-in-china-what-i-learned

Matt White and Kai-Fu Lee
A note on sourcing: This article is not written from Internet research or secondhand reports. Everything described here comes from personal knowledge acquired over eight days of direct meetings, meals, and candid conversations with founders, researchers, engineers, and investors across Beijing, Shanghai, and Hangzhou during the last week of April 2026. Some conversations were public, many were discrete, and all were generous.
I’ve been building relationships in China’s AI and technology community for several years — including hosting Chinese researchers and founders at the PyTorch Conference and engaging with them through the PyTorch Foundation’s hosted projects and ecosystem — and this trip deepened those ties in ways I’m still processing. Any opinions expressed here are my own and not that of my employer or of any of the institutes I am affiliated with.
Where I Went and Who I Met
Over eight days, my schedule was relentless in the best possible way. I made this trip alongside a small but sharp group of fellow travelers: Nathan Lambert (AI2, Interconnects), Florian Brand (Prime Intellect, Interconnects), and the team from SAIL.
Having Nathan and Florian in the room was a genuine force multiplier — between the three of us, we could cover technical depth, policy nuance, and open-source ecosystem dynamics simultaneously, and the conversations we had collectively were richer for it. I’d encourage you to read their own accounts of the trip for perspectives that will complement and in some places diverge from mine.
The itinerary took us across three cities — Beijing, Shanghai, and Hangzhou — each with its own distinct personality and concentration of activity. Beijing is the policy and research capital, home to Tsinghua (pronounced “ching-wa”), DeepSeek, and the government relationships that shape the industry’s direction. Shanghai is the commercial and startup hub, fast-moving and cosmopolitan, where you feel the velocity of the consumer AI market most acutely.
Hangzhou is Alibaba’s home city — quieter, more measured, but quietly dominant in AI infrastructure and platform services, and home to a second DeepSeek office that gave me a chance to spend time with the team across two different settings.
On the AI lab side, I visited Moonshot AI, Z.ai (Zhipu), MiniMax, AIInnovation, 01.ai, DeepSeek, AntGroup / Ant Ling, Alibaba Cloud / Qwen, and Xiaomi, which has been quietly training its own AI models alongside its EV business. On the academic side, I spent time at Tsinghua’s AIR Lab, which sits at the center of a remarkable talent pipeline. And in robotics, I visited three startups that represent the full spectrum of where physical AI stands today: Galaxea, Galbot, and Unitree.
We also sat down with investors from Etna Labs and an early-stage VC fund that I’ll keep unnamed, and spent time with teams at ModelScope (Alibaba’s answer to Hugging Face) and Xiaohongshu (RedNote), the Chinese answer to Instagram and Pinterest.
The social calendar was no less packed. Dinner with Kai-Fu Lee in Beijing — Peking duck and classic Beijing plates, with conversation that ranged across the arc of his career, from his early days at Apple and Google to his current work at 01.AI and his long view on what Chinese AI is actually building toward.
There was a memorable KTV session (Karaoke TV room) with investors in Beijing, evenings with researchers from companies like Moonshot, DeepSeek, Z.ai, AntGroup, and others all sharing the same table, and one particularly memorable visit to an AI-first nightclub in Shanghai where the entire experience — music, lighting, ambiance, bar recommendations — was orchestrated by AI. It was delightfully strange.
Lunches and dinners in Hangzhou had a different texture — quieter, more infrastructure-focused, the conversations as likely to turn to data pipelines and inference costs as to model benchmarks.
The Week the Models Dropped
I flew to Beijing on the week of April 20th, and we could not have picked a better week to travel to China. Leading up to and including the eight days we spent in China — moving between Beijing, Shanghai, and Hangzhou, visiting AI labs, academic institutes, and robotics startups — five major open model releases dropped in rapid succession, almost as if the ecosystem was rolling out the welcome mat:
- Kimi K2.6 (Moonshot AI) — April 20th, Moonshot’s much anticipated 1.1T parameter model scaling to an impressive 300 parallel sub-agent swarm and autonomous coding capabilities competitive with open frontier models.
- Qwen 3.6-27B (Alibaba) — Released two days later, activating only a fraction of its parameters per token, delivering near-frontier performance at a fraction of the cost of Western alternatives.
- MiMo V2.5 Series (Xiaomi) — Published to Hugging Face the same day, a compact but capable family of models with strong reasoning performance and hardware-efficient design from of all companies, an EV company.
- Ling-2.6-1T (InclusionAI) — On April 23rd A trillion-parameter mixture-of-experts coding model optimized for agentic workflows.
- DeepSeek V4 (DeepSeek) — April 24th, landing the same day I did, featuring the 1.6 trillion parameter V4 Pro and the highly efficient V4 Flash, with hybrid attention architecture and a 1 million token context window.
Five labs. Five model drops. One week. In any other context, this would be news. In China in late April 2026, it felt like business as usual.
The Policy Week
The model releases were not the only news that week. While Chinese labs were shipping, both governments were tightening the screws — and three policy developments in rapid succession during the days of my visit reshaped the backdrop for every conversation I had.
The Deterring American AI Model Theft Act. On April 22nd, the House Foreign Affairs Committee advanced this legislation, which would restrict foreign entities from using American frontier AI models as distillation targets for their own training. The proposal reflects a concern in Washington about whether models from American labs are functionally subsidizing Chinese model development.
The irony, not lost on anyone I spoke with in China, is that the primary beneficiaries of that distillation pipeline have largely been Chinese open-source models that American enterprises are themselves now adopting. Restricting it would harm American researchers and developers at least as much as it would constrain Chinese labs. (For more on this see Nathan’s post Distillation Panic.)
China blocks Meta’s acquisition of Manus. On April 27th, just after meeting with Kai-Fu and the 01.ai team, China’s NDRC ordered Meta to unwind its $2–3 billion acquisition of Manus, the agentic AI startup originally founded by Chinese engineers that had relocated to Singapore before Meta announced the deal in December 2025. The NDRC’s statement was terse: the acquisition was prohibited “in accordance with laws and regulations,” and both parties were instructed to withdraw the transaction entirely.
The move was extraordinary in its retroactive scope — Manus engineers had already joined Meta’s AI team, and investors had already received proceeds. Beijing’s intervention was not merely blocking a future deal; it was unwinding a completed one. The Chinese government also issued exit bans on Manus executives under scrutiny.
The message to the Chinese AI ecosystem was unmistakable: strategic AI technology does not leave China, regardless of what corporate restructuring has occurred or which jurisdiction a company has nominally relocated to.
NDRC bars U.S. capital without explicit authorization. The Manus block was not a standalone action. On April 24th — the same day DeepSeek V4 dropped — the NDRC privately notified several leading Chinese AI companies that they must reject U.S.-origin investment in upcoming funding rounds unless they have explicit government approval. The companies named include Moonshot AI, StepFun, and ByteDance.
Moonshot, which was pursuing a funding round then valued around $18 billion and is also considering a Hong Kong IPO, will now see foreign allocation tilt heavily toward Middle Eastern and Hong Kong institutional investors. StepFun — a Tencent-backed multimodal AI startup eyeing a $500 million Hong Kong float — is simultaneously unwinding its offshore red chip structure to meet separate listing requirements, a restructuring that carries significant tax implications.
ByteDance was separately warned that secondary share sales to American investors require Beijing’s sign-off.
The significance of this three-part policy sequence should not be understated. In the span of five days, Washington advanced legislation to restrict Chinese access to American models, Beijing blocked a completed acquisition to prevent Chinese AI technology from reaching an American company, and Chinese regulators asserted veto power over the cap tables of their most strategically valuable AI startups. This is not a trade dispute.
It is the active construction of two separate AI ecosystems, each ring-fenced from the other by an accelerating series of regulatory walls.
I want to be clear about what I observed at the engineering level: none of this changed the conversations I had in labs, over coffee, at dinner. The researchers I met are not policy instruments. They are scientists who want to do great work and compete on benchmarks. But the walls being built above them will inevitably shape what they can build, who funds them, and which communities they can collaborate with.
That is worth caring about — and a concerning trend that I would like to see reversed for the sake of global AI cooperation and advancement.
A Few Words on the Cities Themselves

Impressions show at West Lake in Hangzhou
I want to pause before diving into the labs and say something for readers who haven’t spent time in China recently — or ever — because the cities themselves leave an impression that context requires.
The cleanliness and order will surprise you. Beijing, Shanghai, and Hangzhou are immaculate in a way that puts most Western cities to shame. Streets are swept, infrastructure is maintained, public spaces are orderly. There is a level of civic organization that is visible and felt everywhere you go. If your mental image of Chinese cities was formed by older photographs or secondhand accounts, update it.
Traffic is genuinely another story. The one place where the infrastructure strains under its own weight is the roads. The density of vehicles — many of them EVs, notably — and the sheer volume of urban movement makes traffic in all three cities a real logistical factor. Build in buffer time. The trains, by contrast, are extraordinary — fast, punctual, and convenient.
The scale of development is hard to fully absorb. Construction cranes are a permanent feature of the skyline. Entire new districts materialize between visits. China is still building at a pace and ambition that has no Western equivalent, and you feel that energy in the cities as much as you do in the labs.
But the cities are not only modern. Each one carries centuries of history with extraordinary care.
In Beijing, I made time for the Forbidden City — the 600-year-old imperial palace complex that remains one of the most awe-inspiring built environments on earth — and for the Great Wall, which no photograph or description adequately prepares you for. Standing on it, you stop thinking about data mix and model architecture for a few minutes. The experience is overwhelming.
In Shanghai, the Bund at night is the skyline photograph you’ve seen a thousand times, but it earns its reputation in person — the colonial-era architecture of the waterfront facing down the luminous towers of Pudong across the Huangpu River. We also spent an afternoon at Yu Garden, a sixteenth-century classical Chinese garden tucked inside the old city, where the contrast with the surrounding modernity is deliberately, beautifully jarring.
In Hangzhou, the whole group attended the Impression West Lake — a spectacular outdoor performance staged on the lake itself, directed by Zhang Yimou, using the water, mist, and natural landscape as the stage. It is unlike any theatrical experience I have had. Earlier that day some of the group enjoyed a walk around the perimeter of West Lake, one of China’s most celebrated landscapes, with willow-lined causeways, pagodas, and lotus ponds that have inspired Chinese poets and painters for a thousand years.
It was a genuinely restorative way to process an intense week.
If you ever have the opportunity to make this trip, do not fill every hour with meetings. Leave room for the places. They genuinely matter.
The Culture of Chinese AI Labs
Before getting into the technical and business dynamics, I want to spend some time on culture, because this is where most Western observers get China’s AI ecosystem most wrong.
Humility, not hustle. Chinese researchers, founders, and engineers are genuinely kind, deeply curious, and — in contrast to the personal-brand-building culture of Silicon Valley — largely uninterested in making a name for only themselves. The engineers I met were motivated by the work itself and by ranking on public benchmark leaderboards where their open models compete against other Chinese models and the U.S. APIs (a fundamentally broken means of comparison but a topic for another post). Internal status games were far less visible than I’m accustomed to seeing at American labs.
Not grinding, but focused. I was at one lab on a holiday weekend. Maybe six engineers at their desks. Researchers in China often arrive at 10 or 11 AM and work until 7 PM, with deep focus during those hours. The assumption that Chinese AI workers outwork their American counterparts through sheer hours alone is a myth. They work smart. They are constraint-aware. They do more with less, because they have had to.
(A fair caveat: an empty office on a holiday weekend isn’t a perfect measurement of effort at any AI lab. American labs from OpenAI to Anthropic would look similarly thin in person, since researchers in both ecosystems do a lot of their work from home. The point is not that Chinese labs are quieter — it’s that the “they work nights and weekends harder than us” narrative isn’t borne out by what I actually saw.)
Young and lean. The average age of an AI researcher I met in China was around 25. One lab even shared that they had high school students on their team. Most labs are deliberately small. There are no sprawling campuses of thousands of ML engineers. Teams achieve what they achieve through architectural cleverness, careful data curation, and tight feedback loops — not by scaling headcount or throwing compute at problems.
Open source is in the DNA. Every lab I visited treats open source as a default, not a strategic choice. The question is not “should we open-source this?” but “which parts do we open-source and when?” This is a meaningful cultural distinction. Open source is how they recruit, how they build credibility, and how they engage with the global research community. Truly the democratizing effect of open source and open models helps educate the next generation of AI researchers.
The community vs. the individual. Culturally, China is collectivist in ways that have real implications for how AI labs operate. Where American labs celebrate individual researchers and their works, Chinese labs tend to celebrate the team, the model, the lab. There is, however, still fierce competition — between labs, and sometimes between teams within the same lab.
I was told a story — which I’ll leave specific enough to be illustrative — of two internal teams at the same company running separate experiments on the same problem, neither willing to share intermediate results with the other, both racing to show up at the next internal demo with better numbers. This kind of constructive internal rivalry is not a ubiquitous approach across all labs. Like American labs they have different approaches to motivating and incentivizing researchers.
AI as empowerment, not replacement. This is perhaps the most striking cultural difference I observed, and it deserves to be stated plainly: in eight days of conversations with engineers, researchers, founders, and investors, not a single person framed their agentic AI work as building tools to replace their colleagues. That framing was simply absent.
AI is overwhelmingly understood as a multiplier of individual capability — a way to do more, build more, ship more, start more companies — not as a substitute for human labor. The American discourse around AI is saturated with anxiety about job displacement, and that anxiety is often a tacit constraint on how products are positioned. In China, the same tools are positioned as a way for individuals to escape the constraints of working at a large company at all.
The cultural valence is fundamentally different, and it shapes everything from product design to recruiting pitches to dinner-table conversation.
The talent is staying home — and increasingly never leaving in the first place. One of the most consequential trends I observed: Chinese students who earned advanced degrees at Berkeley, Stanford, CMU, and MIT are no longer defaulting to American AI labs after graduation. They are going home. They are starting companies. They are joining existing AI labs.
The brain drain that once flowed reliably from elite Chinese universities to Silicon Valley is reversing, and it is doing so because the opportunity in China is real. Just as significantly, a growing share of top Chinese students never apply to American institutions at all. Tsinghua and Peking University have built AI programs that the strongest students now actively prefer, both for the quality of the research and for the proximity to the country’s most exciting labs.
The pipeline that once started in California is increasingly starting — and ending — in Beijing.
A bilingual, bicultural research bench. A related observation worth stating directly: the researchers I met in Chinese labs are not a homogeneous group. Most labs are a genuine mix of two profiles — Western-educated, fluently English-speaking returnees who did their graduate work in the U.S. or U.K., and domestically educated, primarily Chinese-speaking researchers who came up through Tsinghua, Peking University, Shanghai Jiao Tong, USTC, or Zhejiang.
The two groups work side by side, often on the same teams, and the interplay between them shapes how ideas move through the lab. The English-speakers maintain the lab’s connective tissue with the global research community — they read papers in real time, engage on social media, attend international conferences.
The Chinese-educated researchers anchor the lab’s deeper expertise in domestic systems work, optimization, and the kind of from-scratch infrastructure building that on-the-job training tends to produce. Neither group is more important than the other; the strongest labs are deliberately mixed.
The window into American AI is X and Hugging Face. When I asked researchers how they keep up with what American labs are doing, the answer was remarkably consistent: X (formerly Twitter) and Hugging Face. X for the discourse — paper announcements, methodological debates, the running conversation among Western researchers about what is and isn’t working — and Hugging Face for the artifacts: weights, datasets, benchmarks, evaluation results.
The fact that X is blocked in mainland China without a VPN does not appear to have meaningfully slowed this. Every researcher I spoke with reads X daily. This is worth holding in mind alongside any policy proposal that imagines an information firewall between the two ecosystems: the firewall, in practice, is porous in exactly the places that matter most, and the porosity is what keeps the global research conversation a single conversation.
Money isn’t everything. In contrast to the multi-year hundreds-of-millions-of-dollar compensation packages touted in the U.S. for top AI researchers, Chinese salaries are much more modest, and that is also reflected in the salaries of AI researchers. Certainly the founders and executives at the top labs enjoy higher compensation but boots-on-the-ground researchers and engineers earn a more modest wage.
Safety is present, not dominant. Most major labs have safety researchers on staff, and the work is genuine. But anyone expecting the kind of existential safety discourse that dominates conversations at Anthropic, or OpenAI will find it largely absent here. In China, the safety conversation centers on content moderation, regulatory compliance, and preventing misuse — practical, near-term concerns rather than long-horizon alignment theory.
This is not because Chinese researchers are naive about the risks of advanced AI; it is a reflection of different institutional priorities, different regulatory pressures, and perhaps a more empirical disposition toward problems that have not yet materialized.
Whether this represents a gap or simply a different philosophy is a conversation worth having — but it is a real and notable cultural difference, and one that I think the global AI safety community should engage with directly rather than talk around.
The AI Labs: Impressions and Insights
DeepSeek

Only the coolest labs have their own coffee cups
If there is a lab that commands universal respect across the entire Chinese AI ecosystem, it is DeepSeek. Every lab I visited cited their innovations — particularly the GRPO algorithm and their distinctive approach to reasoning training — as something that many labs had incorporated into their own work. There is no jealousy here. Just admiration — the kind reserved for people who changed the rules of the game.
I had the pleasure of spending time with the DeepSeek team twice during this visit — once in Beijing and once in Hangzhou, where they maintain a second office. I first met the team last year and have since maintained a strong and cordial relationship with the lab. The Hangzhou visit was more informal: coffee with a small group of friends from the team, the kind of conversation that doesn’t happen in a conference room.
Over dinner in Beijing, I had a long conversation with someone who has been with the company since before it was DeepSeek — since the High Flyer quantitative trading fund days, when Liang Wenfeng was trying to figure out what to build next after a highly successful career in quantitative finance. They were exploring chips in 2019, but the talent wasn’t available. When ChatGPT arrived and the case for large language models became undeniable, DeepSeek was born.
The name and the whale logo were both chosen by internal employee vote.
Technically, the DeepSeek story is one of relentless architectural ingenuity in the face of resource constraint. DeepSeek-V3, released in late 2024, trained on 14.8 trillion tokens and reportedly cost just $5.6 million — a figure that rattled the Western AI industry, which had normalized nine-figure training budgets.
The V4 series, released the day I arrived in China, represents a significant leap: DeepSeek-V4-Pro carries 1.6 trillion total parameters with 49 billion active per token, trained on over 32 trillion tokens including a substantial Chinese-language corpus, and natively supports a 1-million-token context window. The Chinese share of the pretraining data is notable not just as a number — it actually surfaces in the model’s behavior.
Ask V4-Pro a hard reasoning question and you’ll occasionally see Chinese tokens appear in its chain-of-thought before it resolves back to English. The model is thinking in Chinese and reporting in English, which is a useful tell for how deeply the language data shapes internal representations.
The key architectural innovation is a hybrid attention system — Compressed Sparse Attention combined with Heavily Compressed Attention — that makes million-token context practical in production for the first time. At 1 million tokens, V4-Pro requires only 27% of the inference FLOPs and 10% of the KV cache of its predecessor. The smaller V4-Flash delivers even more aggressive efficiency, achieving 10% of V4-Pro’s FLOPs at the same context length.
GRPO remains central to post-training, and the Muon optimizer — first popularized by Moonshot (based on work by Kellar Jordan) and now adopted by DeepSeek — further improves training efficiency. The V4-Flash pricing at $0.14 per million input tokens makes it among the most cost-effective frontier-capable models available anywhere in the world.
DeepSeek today has around 300 people, much smaller than the other labs, most of them in their mid-20s. The business team remains fewer than 10 people — though it’s growing as the lab engages more actively with external partners. There is a philosophical DNA to this company that originates with Liang: no idea is a bad idea, do more with less, innovate, experiment and iterate.
The lab moves as one, no egos, but it is very much a top-down organization with the commander and chief, Liang, the ultimate decider.
Moonshot AI (Kimi)

The white Yamaha piano at Moonshot’s office
Kimi K2.6 dropped on April 20th — just four days before I arrived — and the Moonshot team was in that particular kind of post-launch stillness I’ve come to associate with engineers who have shipped something they genuinely believe in. No chest-beating, no dashboard-watching. Just quiet focus on what comes next.
The office itself is one of the more distinctive I visited in China — closer in energy to a Silicon Valley startup than to a Chinese research institute, with rock-and-roll themed meeting rooms that reflect the personality of CEO and co-founder Yang Zhilin, who used to play in a band while studying at Tsinghua University. His stage name was “Kimi” — which is where the product gets its name.
Yang founded Moonshot in 2023 alongside Zhou Xinyu and Wu Yuxin, leveraging his background as a former Meta AI and Google Brain researcher and Tsinghua faculty member.
The company’s ascent has been extraordinary even by the standards of China’s AI moment: valued at $4.3 billion at the end of 2025, that figure had more than doubled to $10 billion by early 2026, and just this month Moonshot closed a $2 billion round led by Meituan’s venture arm at a $20 billion post-money valuation — making it China’s most heavily funded LLM startup, having raised $3.9 billion in the past six months alone.
Annual recurring revenue crossed $200 million in April 2026, with 20 days of early-2026 revenue reportedly exceeding all of 2025. The growth acceleration behind these numbers is directly attributable to Kimi K2.5 and K2.6.
Technically, Kimi K2.6 is built for agent-first workloads. Its Parallel-Agent Reinforcement Learning training regime allows it to coordinate swarms of up to 300 sub-agents simultaneously, with each sub-agent capable of up to 300 sequential tool calls autonomously. The architecture uses a 1-trillion-parameter Mixture-of-Experts design with 32 billion parameters active per inference, trained on 15.5 trillion tokens of mixed visual and textual data. Context windows extend to 256K tokens.
The model currently ranks as the second most-used LLM on OpenRouter globally — an organic adoption signal that no marketing budget can manufacture. Their Mooncake inference platform, which serves the Kimi chatbot and processes 100 billion tokens daily, earned a Best Paper Award at the USENIX FAST conference. And their MuonClip optimizer — subsequently adopted by DeepSeek for its V4 training — is a concrete example of Chinese labs advancing the foundational science, not just the applications.
Moonshot is one of the Chinese labs most actively engaged with the global research community, and it shows in the caliber of conversation. I expect only bigger and better things from this lab going forward.
Z.ai (Zhipu)
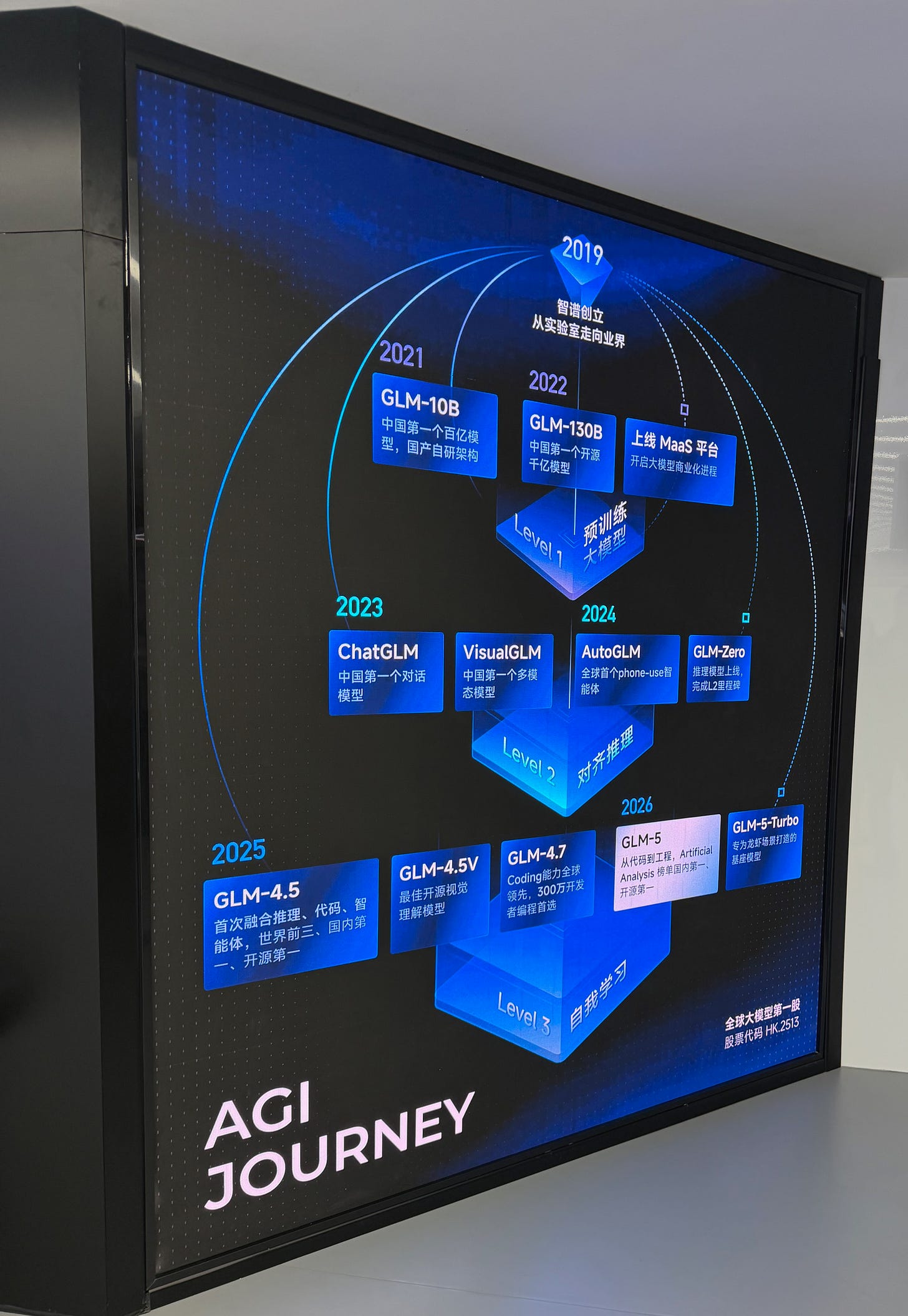
A display panel inside Z.ai’s showroom
Z.ai — added to the U.S. entity list in January 2025 — is a fascinating case study in navigating geopolitical headwinds through technical excellence, community engagement, and a willingness to bet on domestic infrastructure where others hedge.
Founded in 2019 as a spinout from Tsinghua University, Z.ai became the world’s first publicly traded foundation model company when it listed on the Hong Kong Stock Exchange on January 8, 2026, raising approximately HKD 4.35 billion ($558 million USD) at a $7.1 billion valuation. That milestone — preceding OpenAI and Anthropic, both still private — is a structural signal about how differently Chinese AI is capitalized and governed.
Their office has an impressive showroom, and their model roadmap reflects the same ambition. The GLM series — built on the General Language Model architecture originally developed jointly with Tsinghua KEG — has evolved rapidly. GLM-5, released in February 2026, is a 744-billion parameter Mixture-of-Experts model trained entirely on Huawei Ascend chips using the MindSpore framework, with zero dependency on NVIDIA hardware.
This is as much a geopolitical statement as a technical one, and it is credible: production inference also runs on Moore Threads, Cambricon, and Kunlunxin chips. GLM-5 scores 77.8% on SWE-bench Verified — competitive with frontier closed-source models — and its successor GLM-5.1, released open-source in April 2026 under MIT, edged past Claude Opus 4.6 on SWE-Bench Pro at 58.4 vs 57.3.
The pricing is aggressive: GLM-5 API at $1.00 per million input tokens is roughly 5x cheaper than competing frontier models.
The compute picture at Z.ai reflects the broader industry in China — save DeepSeek’s more complete transition to Huawei Ascend: approximately 80% NVIDIA, 20% Huawei Ascend, with the Huawei hardware used primarily for inference. There is a dedicated internal team that tests every domestic chip, but production training deployments are still predominantly NVIDIA-based.
The interesting detail: Huawei is paying top undergraduate students up to 10,000 RMB per kernel to accelerate CANN kernel development — a competitive compensation model that reflects how seriously they are taking chip software parity and ensuring that students are endowed with the skills to develop kernels on their Ascend accelerators. Worth noting on the open-source side: Huawei is also making meaningful upstream contributions to PyTorch to support Ascend as a first-class backend.
This is one of the most concrete examples of a Chinese hardware vendor playing the long game with the global open-source community rather than maintaining everything in a downstream fork — and it’s the kind of behavior more Chinese labs and infrastructure providers should emulate.
I spent time with one of their senior inference engineers, who contributes extensively to both SGLang and vLLM, fully upstream, as a core part of his job. What struck me was the operational discipline around model releases: he described having an entire month of preparation time before each launch, dedicated solely to ensuring that both SGLang and vLLM fully support the new model’s features on day one and that inference is highly performant before the model ever goes public.
That kind of investment in the deployment ecosystem — not just the model itself — is a sign of a lab that has matured beyond the publish-and-pray approach. SGLang in particular has become widely adopted across the Chinese AI ecosystem — arguably more so than vLLM in some quarters — and the engineers building on top of it are largely doing so without formal academic backgrounds in the underlying systems work.
RL infrastructure, custom inference engines, kernel-level optimization — these are skills most Chinese AI engineers acquired on the job rather than in university coursework. The on-ramp into deep systems work happens inside the labs, not before them.
I also heard something from an engineer that stuck with me: his commercial team was quietly pushing back on how much his team was open-sourcing. This tension — between engineers who see open collaboration as professional identity and business teams trying to figure out monetization — is real across the Chinese AI ecosystem. It is not unique to China, but it is felt acutely when your best models are also your best recruiting tools.
Z.ai has publicly committed to continuing to open-source its models post-IPO, and the engineering culture I observed supports that pledge. Whether the commercial pressures remain manageable is a question worth watching.
Alibaba Cloud / Qwen

In front of Alibaba Cloud’s office
The numbers around Qwen (pronounced “chi-wen”) are staggering, and I want to state them plainly before adding the texture: as of April 2026, Qwen has approached 1 billion cumulative downloads on Hugging Face, accounting for over 50% of all open-source model downloads worldwide. In February 2026 alone, Qwen recorded 153.6 million downloads — more than double the combined total of the next eight major players, including Meta, DeepSeek, and OpenAI.
Alibaba has open-sourced nearly 400 models in the Qwen lineup and spawned more than 180,000 derivative versions. More than 90,000 enterprises use the Qwen model family. The consumer Qwen app has reached 203 million monthly active users, ranking third globally after ChatGPT and Doubao. These are not Chinese market statistics. They are global ones.
The Qwen team has built something rare: a full-stack AI platform spanning embedding models, multimodal VLMs, reasoning models, code-specialized models, audio models, and long-context systems — some open, some behind APIs.
Their Qwen 3.6-27B release, which dropped during my visit, demonstrated continued leadership in efficient MoE architectures, delivering near-frontier performance while activating only a fraction of parameters per token — a design philosophy that traces directly to the compute constraint culture I observed across every Chinese lab.
What struck me about the Alibaba Cloud team was the infrastructure advantage that no pure-play lab can replicate. Alibaba’s T-Head division is pursuing deep vertical integration across the AI stack — from the Hanguang AI accelerator chips to the serving infrastructure to the model layer — in a way that mirrors how Chinese EV and robotics companies have come to own their entire supply chains.
Alibaba CEO Eddie Wu has publicly described Qwen as the “operating system of the AI era,” and the ModelScope platform — Alibaba’s answer to Hugging Face and the central repository for Chinese AI development — reinforces that ambition. If you want to track the cadence of Chinese AI releases in real time, ModelScope is where to look.
The visit to the Qwen team in Hangzhou — Alibaba’s home city — had a different atmosphere than the Beijing labs. More measured, more infrastructure-minded, more focused on ecosystem than on any single benchmark. That disposition makes sense for an organization playing the long game at platform scale.
AntGroup / Ant Ling
AntGroup’s AI work is less visible outside China than it deserves to be, and I think that’s partly a function of the company’s profile: most Western observers know Ant as the operator of Alipay, the payments platform connecting over one billion users to more than 10,000 services. The AI work sits beneath that brand surface but is genuinely substantial.
Ant’s model portfolio has grown into a three-family architecture. The Ling series covers general-purpose language models; the Ring series covers reasoning-specialized thinking models; and the Ming series covers multimodal systems handling image, text, audio, and video. The flagship Ling-2.5-1T, released in February 2026, is a trillion-parameter model designed for high reasoning efficiency and native agent interaction, supporting context lengths of up to one million tokens.
Its companion Ring-2.5-1T is notably the world’s first hybrid linear-architecture thinking model. On AIME 2026, Ling-2.5-1T matches the performance of frontier reasoning models that typically require 15,000–23,000 tokens per problem, while using only about 5,890 — a token efficiency ratio that speaks directly to the cost-reduction imperative that defines Chinese AI economics. Both models are available under open source software licenses on Hugging Face and ModelScope.
The Ling-2.6-1T model, released during my visit, continued that trajectory.
What makes Ant’s AI position structurally interesting is the use case specificity. Their focus on financial services, healthcare, and enterprise scenarios gives them something that general-purpose labs don’t have: a defined customer with defined workflows and defined data. The Tbox agent development platform allows enterprise clients to build and deploy agent applications on top of Ant’s models, and the AWorld multi-agent framework is being developed as a next-generation agent infrastructure layer.
Their LingGuang multimodal assistant — which can generate mini-apps in 30 seconds from natural language prompts — which demonstrates that this lab is also highly capable of applying AI.
Visiting Ant in Hangzhou, where the company is headquartered, felt like encountering an organization that has internalized the “practical, inclusive AGI” framing from their CTO’s public statements — and is building systematically toward it rather than chasing benchmark headlines. It is a quieter ambition, but a well-resourced one.
MiniMax

Minimax office entrance
MiniMax is one of the more quietly ambitious labs in China’s AI landscape, and one that I think is underappreciated outside the country. Founded in 2021 by a team of computer vision researchers out of SenseTime and backed by Alibaba, Hillhouse, and Tencent among others, MiniMax went public on the Hong Kong Stock Exchange in January 2026 — one of the first Chinese AI pure-plays to do so.
The IPO was a signal of the lab’s maturation, and the office reflects it: focused, technically deep, and operating with a clear strategic thesis. I had the pleasure of sitting down with the founders over lunch — a long, unhurried conversation that ranged across the technical roadmap, the strategic logic behind their multimedia bet, and the reality of running a public AI company in this market. They are sharp, thoughtful, and genuinely good people, and the lab clearly reflects who they are at the top.
That thesis is a bet on two things: multimedia generation and agentic AI. MiniMax has pushed the envelope on both with their open models while maintaining a separate API surface for access to their most capable video and image generation systems. Their Hailuo video generation model — now at version 2.3 — is one of the most competitive text-to-video systems available, producing realistic 1080p output with strong dynamic expression and visual stability.
Hailuo is the model you’ve likely seen if you’ve used AI-generated video on any major aggregator platform in the past year. It is available through their API and is actively developed in parallel with their open-weight LLM work.
On the language model side, MiniMax-M1 — released open-source under Apache 2.0 — introduced a distinctive architectural bet: their Lightning Attention mechanism, which enables context windows of up to one million tokens at dramatically lower compute cost than conventional attention.
The MiniMax-01 series that preceded it hit 456 billion parameters and a 4 million token context window, and the M1 generation extended those efficiency gains further, consuming only 25% of the FLOPs required by DeepSeek R1 at equivalent long-context generation lengths. This is not an incremental improvement — it is a fundamentally different approach to scaling inference for agent workloads, where long-context persistence is one of the key bottlenecks.
Tying everything together is the MiniMax Agent — a desktop and mobile application that creates a tight ecosystem around their models, allowing users to compose text, images, video, speech, and music generation workflows in a unified interface. Their MCP server is also publicly available, enabling Claude Desktop, and other MCP-compatible clients to tap their generation APIs directly.
This kind of ecosystem thinking — building the model, the API, the consumer application, and the developer tooling as a coherent stack — is exactly the playbook that separates the labs with staying power from those chasing individual benchmark headlines. MiniMax is also a clean example of the hybrid open/closed pattern I describe later in this piece: open-weight LLMs that build community and credibility, paid API surfaces for the highest-value generative models that pay the bills.
ByteDance Seed

ByteDance office entry
In conversations across every lab I visited, the name that kept coming up as the organization to beat was not DeepSeek. It was ByteDance Seed — ByteDance’s core AI research division. Walking into their offices, the contrast with the startup energy of most other labs was immediately apparent. The space felt like a mature company — organized, well-resourced, operating with the quiet confidence of an organization that has already won in one domain and is patiently executing on the next.
The headcount is meaningfully larger than at most Chinese AI labs, the infrastructure investment is visible, and the teams are specialized in ways that reflect genuine organizational scale. This is not a scrappy startup racing to prove itself. It is an established technology powerhouse that has decided AI is the next frontier and is building accordingly.
ByteDance Seed’s output spans the full AI stack in a way that very few organizations anywhere in the world can match. Their Seed2.0 series — comprising Pro, Lite, and Mini variants — delivers strong multimodal understanding with upgraded LLM and agentic capabilities, particularly for long-horizon, multi-step tasks. To be direct about the LLM benchmarks: Seed’s general-purpose language model is competitive but does not sit at the frontier alongside the top models from DeepSeek or Alibaba.
ByteDance themselves have been candid about this, acknowledging gaps in areas like long-tail knowledge. That honesty is, in its own way, a sign of a mature research organization.
Where ByteDance Seed clearly leads is in video generation. Their Seedance series — accepting text, images, and audio as inputs to generate high-definition video in a unified pass — is a genuine frontier capability, sitting at ELO 1,271 on a competitive leaderboard actively contested by well-funded teams at Google, OpenAI, and Kuaishou. The model powers the video features inside Doubao, ByteDance’s flagship AI assistant app and the dominant AI application in China.
As of the end of 2025, Doubao led the domestic AI-native application market with 226 million monthly active users and crossed 100 million daily active users in December 2025 — achieved with the lowest user growth and marketing spend of any product in ByteDance’s history to reach that scale. Nearly every engineer and researcher I spoke with used Doubao daily, not out of obligation but because it is genuinely woven into their digital lives.
Doubao in turn connects into Douyin — the Chinese counterpart to TikTok — through shared infrastructure and a common AI backbone, giving ByteDance a data flywheel and distribution advantage that no other Chinese AI lab can replicate.
Beyond their model and product work, ByteDance Seed had 25 papers accepted at ICML 2025, three as Spotlight papers, spanning LLM inference optimization, speech, image and video generation, world models, and AI for Science. And on the open-source side, they are the originators and maintainers of VERL (Volcano Engine Reinforcement Learning), an open-source RL framework that has become a cornerstone of the training stack for the Qwen team, now exceeding 10,600 GitHub stars.
VERL is part of the PyTorch ecosystem, and the DAPO algorithm — developed collaboratively by ByteDance Seed and Tsinghua AIR on top of VERL — achieved state-of-the-art performance on AIME 2024 as a fully open, fully reproducible release. This is upstream open-source contribution at the frontier level, and it is exactly the kind of contribution the global community should be building on.
All labs have developed their own RL stack using their own environments. This is still viewed as a key area of differentiation, much like fine-tuning was previously. However as times goes on I believe this will be less of a differentiating factor for the AI labs and that they will converge around an open source RL framework while keeping their golden trajectories as a means of differentiation.
Spoiler: One of the Chinese labs is wrapping up post-training on a major model release coming in the next few weeks.
Open Source: The Default, With an Asterisk
Open source has won in China. That is not an exaggeration. The labs I visited treat open-source AI as a starting point, not a strategic concession. Apache 2.0 and MIT licenses are ubiquitous across Chinese model releases — permissive, globally compatible, and deeply familiar to the engineering community.
But the economics of pure open release have forced a pragmatic adaptation: a hybrid model is now the de facto pattern across nearly every lab I visited. Open weights for the strong-but-not-strongest models, building community, recruiting, and credibility — and paid API access for the most capable systems, where the lab’s competitive edge actually lives. MiniMax does this with Hailuo. Alibaba does this with the top tier of Qwen variants. Moonshot does this with the most agentic Kimi capabilities.
The reason is unsubtle: open source does not directly make these labs money, and someone has to pay for the GPUs. The hybrid model is how the Chinese ecosystem has reconciled its genuine commitment to openness with the brute economics of frontier model training.
That said, I want to be direct about two gaps that need closing.
Gap one: Upstream contributions. Chinese AI labs are enormous consumers of open-source infrastructure. They run on Linux, Kubernetes, PyTorch, Ray, vLLM, and SGLang. They benefit daily from thousands of upstream contributions made by developers around the world. But their contributions back are asymmetric. Bug fixes flow upstream reliably. Features — especially the architectural innovations that power their most competitive models — often stay in forks. This is not bad faith; it is a feedback-loop problem.
The pipeline from Chinese lab engineering teams to open-source project maintainers needs to be better, and that requires work on both sides: maintainers who actively engage Chinese contributors, and Chinese engineers who have internal permission and time to contribute.
There are bright spots worth celebrating — Huawei’s PyTorch contributions for Ascend, ByteDance’s stewardship of VERL, Z.ai engineers contributing to SGLang and vLLM as a core part of their day job — and these examples should be the template, not the exception.
Gap two: Model licenses. Chinese labs continue to release models under Apache 2.0 and MIT — software licenses that were not designed for AI models and do not address the specific governance questions that open AI models raise. I’m actively encouraging Chinese labs to adopt purpose-built open model licenses like OpenMDW, which provide clearer terms around use, redistribution, and modification for all asset types (not just software) while remaining permissive.
This is not a policy conversation, but a legal one, and it requires engineering and legal teams to more closely evaluate the text of open source software licenses to understand that open source software licenses were not designed for AI models.
The Economics of Chinese AI
Several economic realities shape how Chinese AI labs operate, and most of them are not well understood outside China.
Compute scarcity drives architectural innovation — and the Chips Act has not had its intended outcome. The Export Controls Act and subsequent restrictions on advanced semiconductor exports were designed to slow Chinese AI capability development by restricting access to leading-edge GPUs. The honest assessment, after a week of talking to the labs actually subject to those restrictions, is that the policy has not achieved its intended outcome.
It has slowed brute-force scaling, yes — but it has simultaneously forced two adaptations the policy authors did not seem to anticipate. The first is architectural: when you can’t throw more compute at a problem, you are forced to find smarter solutions, and the result has been some of the world’s most efficient model architectures. DeepSeek’s efficiency innovations are the most famous example, but this pattern repeats across every lab I visited.
The second is industrial: the restrictions have accelerated, not deterred, Chinese domestic chip development, and have catalyzed the formation of a new ecosystem of chip startups specifically focused on AI workloads. The supply pressure created the demand for the alternative supply, and Chinese capital and policy responded.
Chinese labs are investing heavily in domestic silicon — and a new wave of chip startups has emerged. The compute constraint has done more than reshape model architectures — it has accelerated a national push to build a domestic chip stack. Huawei (Ascend), SMIC (fabrication), Cambricon (training and inference accelerators), Moore Threads, and Kunlunxin are all receiving meaningful state support in the form of grants, procurement guarantees, and tax incentives.
Alongside these established players, a host of newer AI-chip startups has emerged specifically to address the gaps in the domestic stack — efforts that simply did not exist at this density before the export controls. Many will fail; the surviving subset will form the backbone of a parallel hardware ecosystem. The labs I visited are actively testing every one of these chips, and several have production inference running on them today.
Training parity is not yet there for most workloads, but the gap is closing faster than most Western observers realize, and DeepSeek’s transition to Huawei Ascend is a leading indicator.
Some training has moved offshore. One nuance that doesn’t get discussed enough: not all Chinese AI training happens inside mainland China. Several labs are running meaningful portions of their training workloads on infrastructure based in Singapore and other jurisdictions where leading-edge chip access remains available. This is not a secret in the ecosystem, and it is not framed as evasion — it is simply pragmatic infrastructure planning by globally-minded teams.
But it is worth understanding as another data point in the conversation about whether export controls are achieving their stated goals. The compute, in many cases, is being accessed; the geography has just shifted.
The infrastructure giants are uniquely positioned. ByteDance, Alibaba, and Tencent are all among the largest data center operators in China, with hyperscale infrastructure footprints that no pure-play AI lab can match. This matters more than it might first appear: training frontier models requires not just chips but power, cooling, networking fabric, and operational expertise at scale.
The labs that already operate this infrastructure for their core consumer businesses can absorb AI workloads with marginal additional capex, while their competitors are paying retail for cloud capacity. Over a multi-year horizon, this structural advantage is hard to overstate.
There is no data economy. China does not have a robust commercial data market the way the United States does. The consequence is that pre-training data is largely internet-sourced — Common Crawl, standard web corpora — supplemented by proprietary datasets and, to varying degrees, distillation from American API providers and other open models. This is not unique to China; it reflects a structural difference between the two ecosystems.
Whether a Chinese data economy begins to develop is an open question, but the conditions for it don’t yet exist.
English data still dominates pretraining — even for Chinese labs. This caught me off guard when I first internalized it. The pretraining corpora for nearly every Chinese frontier model are predominantly English, with Chinese as a meaningful but minority slice of the data mix and additional smaller allocations for other languages. The reason is structural: the global open-source benchmark suite — MMLU, GSM8K, MATH, GPQA, SWE-bench, HumanEval, AIME — is overwhelmingly English.
If you want to compete on the leaderboards that matter for global credibility, your model has to be excellent in English first. DeepSeek V4 is a notable variation on this — the team weighted Chinese data more heavily in pretraining than most peers, and as I noted in the DeepSeek section, you can watch that choice play out in real time during reasoning, where Chinese tokens occasionally surface in the chain-of-thought before the model resolves back to English.
The government has not picked winners. There is a common assumption that Chinese AI labs are state-directed. The reality is more nuanced. AI is a nationally identified critical technology in China, and there are real subsidies — discounted compute, government grants, procurement preferences, and a deliberately subsidized inference token economy that makes API access dramatically cheaper than market rates. But the competitive landscape between labs is fierce, ungoverned, and occasionally brutal.
DeepSeek and Alibaba compete genuinely. Moonshot and Z.ai are not coordinating. The government has created conditions for competition, not a command economy for AI.
Subsidies alone don’t fund a lab. Despite the available state support, no Chinese AI lab has been able to run on subsidies alone. Every lab I visited has had to raise external capital — venture, strategic, or eventually public markets — and the IPO path is becoming increasingly important. Z.ai listed on the Hong Kong Stock Exchange in January, MiniMax followed weeks later, Moonshot is reportedly considering its own HKEX listing, and StepFun is targeting a $500 million float.
The remaining frontier labs are running the math on whether to follow.
Researchers are not getting rich. Chinese AI researchers make a fraction of what their American counterparts command. This is not always a disadvantage — it reduces some of the mercenary dynamics you see in American AI hiring — but it creates real talent pipeline pressures as the demand for skilled ML researchers grows faster than compensation can follow.
Software is free. One of the most consequential cultural differences I observed: Chinese users, broadly, do not pay for software. This shapes product expectations, business models, and the entire commercial logic of Chinese AI companies. It is why the API is the primary monetization vehicle, and why Chinese labs are so focused on inference efficiency and cost reduction.
Academia is compute starved. The top AI universities in China like Tsinghua do not have the amount of compute needed to facilitate deep experimental research and instead they rely on public-private partnerships. This is not too different from the model employed in the U.S. however in the U.S. we have federally operated compute clusters that are made available for experimental research originating in academia like Oak Ridge National Laboratory.
ByteDance and Alibaba: The Ones to Watch
I want to make an observation that might surprise some readers: in conversations across multiple labs, the names that kept coming up as the companies to watch long-term were not DeepSeek or Moonshot. They were ByteDance and Alibaba. Alibaba’s Qwen series has achieved the widest enterprise adoption of any Chinese open model, including significant penetration into U.S. enterprise deployments, and Alibaba’s vertical integration through T-Head and ModelScope gives them platform leverage no pure-play lab can match.
ByteDance’s infrastructure scale, data assets through Doubao and Douyin, and engineering depth at Seed position them as a genuine long-term contender. Xiaomi deserves a mention in the same breath for the same structural reasons — infrastructure, capital, and a real consumer hardware channel that few AI-native startups can replicate.
The Agentic Moment
Every lab I visited was deeply focused on agentic AI. The viral adoption of personal agents, particularly OpenClaw, is genuinely widespread, but something more interesting is happening: Hermes Agent is gaining significant ground as the agent of choice at Chinese AI labs and enterprise deployments. On the consumer side, Doubao — ByteDance’s AI assistant app — is enormously popular among the general public.
Nearly everyone I met used it daily, and its tight integration with ByteDance’s broader ecosystem gives it a stickiness that pure model quality alone cannot explain.
One observation on developer tooling that I did not expect to come away with so clearly: Claude Code is genuinely loved by Chinese engineers. It came up unprompted, repeatedly, across labs and over meals. What was equally striking — and telling — was what didn’t come up: Codex and Cursor were essentially never mentioned. Not dismissed, not criticized. Simply absent from the conversation.
In a community that talks openly and enthusiastically about every tool they find useful, that silence speaks for itself.
The one-person company — what Chinese business culture is calling the OPC or solopreneur model — is a source of genuine excitement. The promise of agentic AI enabling a single individual to build, operate, and monetize a business through their agents has captured the Chinese entrepreneurial imagination in a way that feels culturally authentic.
In a society that values collective contribution, the idea that one person can multiply their impact through intelligent systems resonates differently than it does in the West. It is also worth reiterating: this excitement does not come paired with the anxiety about AI eliminating jobs that pervades the American conversation. The frame is additive, not substitutive — agents make the individual more capable, not redundant.
Robotics: China Is Playing a Different Game

Matt White, Jiyang Gao (Galaxea AI CEO) and Nathan Lambert
The Scale of the Ambition
Before I describe what I saw in the robotics labs, some context: over 150 Chinese companies are now developing humanoid robots, and more than 330 new robot models were unveiled in 2025 alone. The entire industry grew at a rate exceeding 50 percent annually, and the Chinese National Planning Commission declared the sector a key strategic industry within the framework of the 15th Five-Year Plan (2026–2030). Chinese companies produced 87% of the roughly 13,000 humanoid robots shipped worldwide last year.
These are not abstract statistics. Walking through the robotics facilities I visited, you feel the momentum. The government is not just subsidizing research — it is subsidizing demand, creating procurement orders that give startups something to build toward.
What I Saw at Galaxea, Galbot, and Unitree

Wang Xingxing (Unitree CEO) and Matt White
Unitree is the clear market leader — ranked #1 globally by Omdia for 2025 shipments, with 5,168 units and a 39% market share. Their approach is distinctive: ship early, ship imperfect, improve through deployment data. This philosophy — which mirrors how Chinese EV companies have operated — gives them a data flywheel that pure research labs cannot replicate. I had the chance to meet with Wang Xingxing, Unitree’s founder and CEO, during the visit.
He is exactly the kind of operator-engineer this industry needs more of — direct, hardware-obsessed, and genuinely warm in person. The cultural ethos of the company maps cleanly to his personality, which is true of every lab I visited but worth noting here because Unitree’s market position is unusual enough that it’s tempting to assume the leadership style is more distant than it is. It isn’t.
Galaxea and Galbot represent the next generation of robotics startups, both deeply focused on what everyone in the industry agrees is the hardest unsolved problem in physical AI: dexterous hands. Manipulation — the ability to handle objects with the kind of fine motor control humans develop in childhood — remains robotics’ great open challenge. Both companies are making progress through careful hardware design and data collection, but nobody is claiming victory here.
Across all three companies, I observed a consistent technical posture:
- Vision, sensors, and actuators are handled by proprietary VLA (Vision-Language-Action) models that each company develops internally.
- Language understanding, task decomposition, and reasoning are handled by an off-the-shelf LLM — almost universally, Alibaba’s Qwen.
- Training data is primarily teleoperated rather than simulated, with real-world RL data collected from actual task execution. Imitation learning is explored but not the first choice.
- Operating systems include both ROS (Robot Operating System) and Zephyr, the real-time OS maintained by the Linux Foundation — a fact that speaks to the reach of open-source infrastructure in the robotics space.
The consensus across the robotics engineers I spoke with: VLA models are falling short of what’s needed for general manipulation, and the future lies in world models — learned simulations of physical reality that allow robots to reason about their environment before acting in it. This is a multi-year research horizon, and everyone knows it.
One theme that came up repeatedly across all three companies: the desire for a stronger open-source ecosystem specifically for robotics. The AI lab community has rallied around shared infrastructure — PyTorch, vLLM, SGLang — and the robotics community is hungry for the equivalent. Today, every company is rebuilding similar pieces of stack internally: data collection tooling, teleoperation interfaces, simulation environments, VLA training pipelines, evaluation harnesses.
The engineers I spoke with would happily contribute to a shared base if the right project existed. This is a real opportunity for shared and open collaboration before the ecosystem becomes permanently fragmented.
The Honor Robot and What It Actually Means
Just days before I arrived in Beijing, Honor’s humanoid robot “Lightning” blazed through a 13-mile race in just 50 minutes and 26 seconds, besting all 12,000 human competitors and even surpassing the human world record for a half-marathon. Hundreds of millions of people watched livestream coverage of the race across various platforms.
The race was extraordinary and, like most robot demonstrations, requires careful interpretation. Only 38 percent of the event’s entries ran autonomously; the rest were piloted remotely. And all of the robots ran on a dedicated, rehearsed course, with support crews trailing behind. Critics were quick to note that impressive locomotion does not equal general competence. They are right. But they are also missing the point.
The Beijing Half Marathon is not about what robots can do today. It is about the pace of progress and the cultural signal it sends. Last year, only 6 of 21 robots finished the course, and the fastest took nearly three hours. This year, multiple robots posted sub-one-hour times. Since 2020, Chinese firms have filed five times more humanoid-related patents than U.S. firms. The trajectory matters as much as the snapshot.
The Robotics Bubble Question
I want to be honest about something I heard from engineers and investors alike: the possibility that China is approaching a robotics bubble. Chinese officials at the NDRC have publicly warned about “speed” and “bubble” risks in the humanoid robotics industry, noting that more than half of China’s humanoid robot companies are startups or cross-industry entrants.
The analogy to China’s e-bike industry — where explosive growth produced massive overcapacity and dramatic consolidation — is one I heard more than once.
The investors I spoke with were not dismissive of this risk. They were calibrated about it. The view from the tables I sat at: there will be winners and there will be losers, and the companies with genuine hardware differentiation, proprietary data flywheels, and defensible manufacturing relationships will survive. Companies that are chasing government subsidies without a real product will not.
Other Stops: Xiaohongshu, Xiaomi, and ModelScope
Xiaohongshu (RedNote)

Matt White at Rednote Office
RedNote exploded into global consciousness in early 2025 when American TikTok users flooded the platform during a ban scare. The platform now has over 300 million monthly active users, and in 2025, Xiaohongshu introduced Diandian, an AI-powered search tool aimed at improving content discovery. Xiaohongshu recorded almost 600 million daily search queries in Q4 2025, reportedly half that of Baidu — and doubled over the past year.
What people don’t fully appreciate about Xiaohongshu is how deeply AI has been integrated into the platform’s core recommendation and discovery systems. The platform processes 10s of billions of search queries monthly, and its recommendation engine combines semantic understanding with behavioral signals in ways that are genuinely sophisticated.
For younger Chinese consumers, Xiaohongshu has become the primary search engine for product research and lifestyle decisions — a role that Google and TikTok split in the West, here unified in a single platform.
Xiaomi

Grade A Xiaomi swag
Xiaomi’s presence in my schedule was one of the more surprising highlights of the trip. Most Westerners think of Xiaomi as a smartphone company. Increasingly, that framing is outdated. Xiaomi has built a genuinely formidable EV business — the Xiaomi SU7 is a vehicle that has left more than one American auto executive visibly rattled after test driving it. Ford CEO Jim Farley reportedly spent six months driving one.
When asked why he chose to drive a Xiaomi SU7 rather than a Tesla to evaluate his competitors, Farley said, “Nothing against Tesla. They’ve been doing great, but you know, they really don’t have an updated vehicle.”
What Xiaomi is doing in AI — training its own models, including the MiMo series released during my visit — is the piece of the story that deserves more attention. Their AI work is not separate from their EV work. It is deeply integrated. The vehicles make extensive use of AI for navigation, driver assistance, voice interfaces, and in-cabin experience. Huawei’s systems are embedded in the product layer. As Farley noted about Chinese EVs broadly: “They have far superior in-vehicle technology. Huawei and Xiaomi are in every car. You get in, you don’t have to pair your phone. Automatically, your whole digital life is mirrored in the car.”
ModelScope

The most comfortable hat I received on this trip
ModelScope — Alibaba’s answer to HuggingFace, and the platform most Chinese developers use as their first stop for model discovery and deployment — is larger and more capable than most Western practitioners realize. It functions as the central infrastructure for the Chinese open-model ecosystem: model hosting, dataset repositories, evaluation pipelines, and developer documentation.
A Word on EVs and Batteries
I want to spend an extra paragraph on this, because the EV question is genuinely consequential and most American observers underrate it. China is not slightly ahead in electric vehicles — it is structurally ahead, and the gap is widening on three independent dimensions: price, technology, and supply chain.
On price, Chinese OEMs are routinely selling capable EVs at price points that would be unprofitable for any American carmaker, and they are doing so while still earning margin, because their supply chain is vertically integrated from raw battery materials through final assembly.
On technology, the in-vehicle experience — UI, voice integration, OTA updates, AI-driven driver assistance, smartphone-to-car continuity — is at least one full generation ahead of what is shipping in American showrooms today. The cars feel like extensions of the digital lives their drivers already live, because the same companies build both.
And on supply chain, China refines roughly 70 to 80 percent of the world’s processed lithium, cobalt, and battery-grade graphite, and Chinese firms hold dominant positions in cathode chemistry, separator manufacturing, and battery cell production through CATL and BYD. The U.S. is not behind on any one of these dimensions — it is behind on all three simultaneously, and the dimensions reinforce each other. Tariffs can slow the timeline; they cannot reverse the structural position.
This is a topic that deserves its own piece, but it would be dishonest to write about Chinese tech in 2026 without saying it plainly.
What I’m Watching Next: Quantum AI
I want to briefly flag something I didn’t have time to explore deeply on this trip but expect to write about in the future: quantum computing. China has designated quantum technology as a top national strategic priority in its 15th Five-Year Plan, with explicit goals around commercialization.
The intersection of quantum and AI is an area where I expect to see significant Chinese activity over the next 3–5 years, and it is a domain where global collaboration — if it can be maintained — could produce outcomes that benefit everyone. More on this in a future piece.
What I’m Bringing Back: Recommendations for the Open Source Community
Eight days of conversations distilled into a few concrete asks for the global open-source AI community:
Engage Chinese contributors, don’t wait for them. Chinese engineers are actively using your projects. Many have fixes, optimizations, and ideas that never make it upstream because the communication channels are informal, the cultural barrier to initiating is higher, and the internal permission structures are not set up for it.
Project maintainers should actively cultivate relationships with Chinese contributors, hold community calls at times that work for Asia-Pacific time zones, and recognize Chinese contributions explicitly.
Build feedback loops, not one-way streets. The Chinese AI ecosystem is generating some of the world’s most important infrastructure research. VERL, DAPO, SGLang contributions from Z.ai, Huawei’s PyTorch work for Ascend — these are not peripheral. They are frontier. A stronger upstream contribution pipeline benefits everyone.
Help Chinese labs adopt better model licenses. Apache 2.0 and MIT are good software licenses and poor AI model licenses. The Linux Foundation and its partners are well-positioned to provide guidance and tooling that makes adopting appropriate open model licenses easy and clearly beneficial.
Convene an open-source robotics ecosystem before it fragments. The robotics community is at the same inflection point the LLM community was at four years ago. The base layers — data tooling, simulation, teleoperation, VLA training — are still being built in silos. A neutral, well-governed home for shared infrastructure would save the industry years.
Open source is borderless. Export controls affect hardware. They affect capital flows. They do not affect open-source software, and the attempt to restrict it would harm American researchers and companies as much as it would harm Chinese ones. Open science is how we make progress together.
Coming Back: Macau and Alibaba, May 27–29
I will be returning to China later this month. On May 27th, I’ll be giving a talk at Alibaba on the true impact of AI on software development — a topic I have strong views on and am looking forward to testing against one of the world’s leading engineering organizations. On May 29th, I’ll be delivering a keynote on Physical AI at BEYOND Expo in Macau, followed by a week of additional visits to labs, universities, robotics companies, and EV facilities.
If you’d like to connect during my trip, reach out to me on X/Twitter or LinkedIn.
A Final Note on Geopolitics and the Open Source Imperative
With the Trump administration actively considering regulation of AI models — including proposals to protect American models from distillation by non-American entities — and President Trump’s visit to China this week, the conversation around open AI is arriving at a political inflection point.
I want to be precise about what I observed: at the engineering level, there is effectively no “US vs. China.” The researchers I met have colleagues and friends at American labs. They trained on datasets built by international communities. They push code to shared repositories. They cite each other’s papers. The geopolitical tension lives at the policy level.
At the technical level, global AI research is one interconnected community, and any attempt to wall it off will harm American innovation as much as it constrains Chinese access.
The Chinese AI ecosystem is not a threat to be contained. It is a community to be engaged. The question is whether American policy — and American companies — choose engagement or isolation. Based on what I saw across eight days in Beijing, Shanghai, and Hangzhou, the Chinese ecosystem will continue to advance regardless of that choice. The only variable is whether American researchers and companies are at the table when it does.
Open source is the unifier. It is the breaker of walls and the builder of bridges. It is the one element of this story that remains unaffected by export controls, capital restrictions, or entity lists, and it is the reason a researcher in Shenzhen and a researcher in Seattle can still meaningfully be said to be working on the same problem.
Whatever shape the path to AGI eventually takes, its spirit must persist along the way — because the alternative is a future in which two ecosystems advance in parallel, never learning from each other, each making the same mistakes twice. That outcome serves no one. We have built something rare in the open-source AI community over the last decade: a genuinely global conversation. It is worth defending.
Acknowledgments
A trip like this is only possible because of the generosity of the people who open their doors, share their tables, and trust you with candid conversation. A few thank-yous are in order.
To Caithrin Rintoul and the team at SAIL — thank you for the partnership in organizing this trip and for the care you put into every detail of the itinerary. SAIL’s work in building bridges across the global AI community is genuinely important, and I’m grateful to have been part of this delegation alongside Nathan and Florian.
To the AI labs that hosted us — DeepSeek, Moonshot AI, Z.ai (Zhipu), Alibaba Cloud / Qwen, MiniMax, AntGroup / Ant Ling, ByteDance Seed, 01.AI, AIInnovation, and Xiaomi — thank you for the hospitality, the technical depth, and the willingness to engage with hard questions. The quality of the conversations was a direct reflection of the quality of the people in those rooms.
I am particularly grateful to the founders of MiniMax, who made time for a long, generous lunch and a conversation that I’m still drawing on.
To the robotics labs — Unitree, Galaxea, and Galbot — thank you for showing me where physical AI actually stands today, not where the marketing materials claim it stands. The dexterity problem is genuinely hard, and the honesty about that was refreshing. A special thank you to Wang Xingxing for taking time to sit down at Unitree.
To Tsinghua AIR Lab, ModelScope, and Xiaohongshu (RedNote) — thank you for the access and the candor about how your respective ecosystems actually work.
To Kai-Fu Lee — thank you for the dinner in Beijing and for the long view. Few people in our industry have your perspective on the arc of how this technology developed, and fewer still are as generous with sharing it. The Peking duck was excellent. The conversation was better.
And to the many people I haven’t named here — the researchers who walked me through their work, the founders who fielded questions over dinner, the investors who shared candid views over KTV, the engineers who patiently fielded my questions about RL infrastructure late into the evening — thank you. This piece is yours as much as it is mine.
Matt White is the Global CTO of AI at the Linux Foundation and CTO of the PyTorch Foundation and LF AI & Data. He was the founding CTO at the Agentic AI Foundation. He is a champion for open-source AI and open science, and works to ensure that open-source remains the first path of choice when building AI systems and training models.
Connect & Follow
- Matt White — LinkedIn · X / Twitter · Substack
- Nathan Lambert & Florian Brand — Interconnects · X / Twitter
- SAIL — blog.readsail.com